
Editorial Mai 2018
Architektur in Business Intelligence
von Michael Müller
Michael Müller ist fast 20 Jahre als Berater im Bereich Business Intelligence tätig. Seine Schwerpunkte sind Datenmodellierung und -architekturen, Data Vault und Data Warehouse Automation. Er ist im Vorstand der Deutschsprachigen Data Vault User Group und im Advisory Board für die Data Modeling Zone Europe, einer Konferenz mit 5 Tracks für Datenmodellierung und -architektur sowie Business Intelligence.
Architekturen in Business Intelligence sind heute meist Sammlungen von Tools. Betrachtet man jedoch zuerst Personen, Prozesse und Informationen, erhält man neue Perspektiven und Möglichkeiten. Häufig sind die Probleme nicht in den Tools, sondern in der Organisation der Daten. Eine gute Architektur sollte die Verantwortlichkeiten zwischen den beteiligten Parteien gut verteilen. Mit diesen Maßnahmen hat ein Unternehmen die Werkzeuge für den Umstieg auf eine Data Driven Company zur Hand.
In den letzten Jahren habe ich einige Projekte zur Data Warehouse Automation durchgeführt. Mit der Umsetzung konnten wir die Implementierungszeiten deutlich senken. Was vorher 12 bis 15 Monate gedauert hat, konnte auf einmal in 2 bis 3 Monaten realisiert werden.
Parallel dazu sind viele andere Themen auf einmal sehr stark in den Vordergrund getreten: die Datenakquisition hat nicht funktioniert, die Fachkonzepte hatten Lücken bzw. fehlte die Ausdrucksmöglichkeit auf Fachbereichsebene, die Datenqualität war nicht gut genug, die Referenzdaten (Master Data Management) waren ungenügend, etc.
All diese Probleme waren nicht neu, nur waren sie bisher auf 12 bis 15 Monate verteilt. Mit der kürzeren Umsetzungszeit war die Aufmerksamkeit auf diese Themen viel höher, bisher lief so etwas nebenbei, nun war es auf einmal ein zentrales Hemmnis des Projekts. Und dass, obwohl diese Themen nicht Bestandteil des Projekts waren.
Hier ist die Abgrenzung der Aufgaben und die Verteilung der Verantwortlichkeiten nicht vor Beginn des Projekts erfolgt. Hinter dem Problem der Datenintegration hatten sich viele andere Probleme versteckt (und bei jedem Kunden individuell eigene Probleme). Einer meiner Kunden meinte: „Nehmen wir den Standard“. Leider gibt es keinen Standard für die Organisation der Daten im Unternehmen oder für eine Architektur der Business Intelligence.
Es gibt ein viele gute Denkansätze und Initiativen. So hat Barry Devlin hat in seinem Buch ‚Business Un-Intelligence‘ beschrieben, welche konzeptionelle Arbeit zu leisten ist, um aus Daten Informationen zu machen. Neben den Daten sind die Prozesse zu betrachten und final müssen die Personen betrachtet werden, die die Daten erstellen und die diese Daten nutzen.
Neben der Datenintegration und der historischen Speicherung der Daten, neben den eigentlichen Reports, Analysemöglichkeiten und der Vorhersage mit Data Mining braucht es verschiedene Artefakte, die den Prozess der Informationsbildung unterstützen:
Data Strategy: Die Strategie des Unternehmens im Umgang mit den Daten. Nicht unbedingt nötig, wenn die Ziele des Unternehmens klar sind und alle Beteiligten wissen, was zu tun ist. Wenn jedoch das Unternehmen eine Data Driven Company sein will, sollte hier stehen, was das bedeutet. Und eine sinnvolle Strategie ist auch, zunächst einmal herauszufinden wie Daten das Unternehmen weiterbringen können. Die Data Strategy soll die Mitarbeiter in die Lage versetzen, die richtigen Entscheidungen zu treffen.
Data Governance: beantwortet die Frage, welche Daten wo im Unternehmen sind. Leider kann dies ganz erheblichen Aufwand nach sich ziehen. Es sind Data Stewards festzulegen, die für bestimmte Teilbereiche die Verantwortung übernehmen. Es sind Abstimmungsrunden zu schaffen, um die einzelnen Teile besser aufeinander abzustimmen. Der Gewinn ist erheblich, es gibt nun einen dedizierten Platz an dem hinterlegt ist, welche Daten vorhanden sind. Über die Abstimmung können Friktionen zwischen den Systemen und vor allem zwischen operativ und dispositiv beseitigt werden. Die Kosteneinsparung ist erheblich. Meist gibt es bereits ein rudimentäres System, dass es nur zu optimieren gilt. Mit einem klaren Blick auf möglichst kleinen Aufwand und dem Fokus auf Konsens im Sinne von „damit kann ich arbeiten“, können hier sehr gute Ergebnisse erzielt werden.
Information Requests: sind die Fachkonzepte für Informationen, die benötigt werden. Dabei ist egal, ob es sich um einfache Berichte, komplexe Analysemöglichkeiten oder Data Mining handelt. Dies ist der Weg, wie jemand aus dem Fachbereich an Informationen kommt. Wenn diese mit den Begriffen aus dem Data Governance verknüpft sind, wird eine Umsetzung deutlich einfacher. Diese Artefakte sind eng miteinander verknüpft und beschleunigen insgesamt die Informationsgewinnung.
Betrachtet man die Thematik aus diesem Blickwinkel, ist das Thema Datenarchitektur vor allem ein organisatorisches Thema. Hierzu hat Martijn ten Napel mit seiner connected architecture (https://preachwhatyoupractice.nl/en/2018/01/connected-architecture-framework-emphasis-on-the-organisation-of-data/) einen guten Beitrag geliefert. Aufbauend auf der Arbeit von Barry Devlin hat er verschiedene Prozesse aus der Sicht von Nutzergruppen beschrieben:
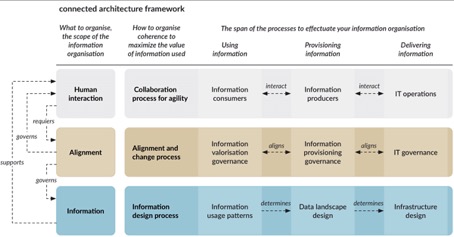
Dabei muss ja nicht immer eine komplette Data Governance umgesetzt werden. Auch hier sind schlanke clevere Prozesse denkbar, die nur das jeweils relevante umsetzen und sich im Lauf der Zeit anpassen.
Dies ist ein kultureller Wandel – Daten rücken in den Mittelpunkt und sind nicht mehr nur ein IT Problem. Die Abstimmung zwischen den Bereichen wird enger verzahnt. Eine gute konsensorientierte Kultur ist hierbei essentiell, um sich auf das wesentliche zu beschränken. Diese Abstimmungen sind kein Selbstzweck, sondern ermöglichen die optimale Nutzung von Daten im gesamten Unternehmen.
Nun kann für die Integration und Aufbereitung der Daten eine schnelle und adaptive Architektur gewählt werden. Das 4 Quadranten Modell von Roland Damhof (http://www.b-eye-network.com/blogs/damhof/archives/2013/08/4_quadrant_mode.php) bietet eine exzellente# Entscheidungsgrundlage, welche Daten sofort bereitgestellt werden und für welche zunächst Anforderungen formuliert werden müssen. Auf einer zweiten Achse wird abgebildet welche Daten automatisiert ausgewertet werden und welcher Teil der Auswertung ad-hoc und initiativ erfolgt. Dies ist ein Modell mit dem diese Prüfung auf regelmäßiger Basis erfolgen kann und bietet somit die Chance für die Weiterentwicklung und beständige Verbesserung der Datenintegration.
Bei der Datenintegration bieten sich viele neue Möglichkeiten. Die Methoden haben hier in den letzten Jahren einen Quantensprung gemacht. Basierend auf einer Architektur, die Integration und Aufbereitung in einzelne Aspekte getrennt hat, lässt sich das automatisieren und somit radikal beschleunigen. Das geht sowohl nach klassischem Kimball als auch nach Data Vault. Und damit lassen sich die neuen Wünsche auch mit der bestehenden Mannschaft realisieren.
Die Transformation zu einer Data Driven Company ist nicht nur ein Tool Thema. Vielmehr sind auch die organisatorischen Voraussetzungen zu schaffen. Und selbst, wenn man nicht gleich zu einer Data Driven Company werden will, eine gute Architektur, die auch die Organisation der Prozesse im Blick hat, sorgt einfach für eine gute hausinterne Informationspolitik, so dass alle notwendigen Informationen zum Handeln verfügbar sind.